 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Recurring Vulnerabilities from Black-Box LLM-Generated Software
Feb 02, 2026LLMs are increasingly used for code generation, but their outputs often follow recurring templates that can induce predictable vulnerabilities. We study \emph{vulnerability persistence} in LLM-generated software and introduce \emph{Feature--Security Table (FSTab)} with two components. First, FSTab enables a black-box attack that predicts likely backend vulnerabilities from observable frontend features and knowledge of the source LLM, without access to backend code or source code. Second, FSTab provides a model-centric evaluation that quantifies how consistently a given model reproduces the same vulnerabilities across programs, semantics-preserving rephrasings, and application domains. We evaluate FSTab on state-of-the-art code LLMs, including GPT-5.2, Claude-4.5 Opus, and Gemini-3 Pro, across diverse application domains. Our results show strong cross-domain transfer: even when the target domain is excluded from training, FSTab achieves up to 94\% attack success and 93\% vulnerability coverage on Internal Tools (Claude-4.5 Opus). These findings expose an underexplored attack surface in LLM-generated software and highlight the security risks of code generation. Our code is available at: https://anonymous.4open.science/r/FSTab-024E.
Step-Wise Refusal Dynamics in Autoregressive and Diffusion Language Models
Feb 01, 2026Diffusion language models (DLMs) have recently emerged as a promising alternative to autoregressive (AR) models, offering parallel decoding and controllable sampling dynamics while achieving competitive generation quality at scale. Despite this progress, the role of sampling mechanisms in shaping refusal behavior and jailbreak robustness remains poorly understood. In this work, we present a fundamental analytical framework for step-wise refusal dynamics, enabling comparison between AR and diffusion sampling. Our analysis reveals that the sampling strategy itself plays a central role in safety behavior, as a factor distinct from the underlying learned representations. Motivated by this analysis, we introduce the Step-Wise Refusal Internal Dynamics (SRI) signal, which supports interpretability and improved safety for both AR and DLMs. We demonstrate that the geometric structure of SRI captures internal recovery dynamics, and identifies anomalous behavior in harmful generations as cases of \emph{incomplete internal recovery} that are not observable at the text level. This structure enables lightweight inference-time detectors that generalize to unseen attacks while matching or outperforming existing defenses with over $100\times$ lower inference overhead.
You Had One Job: Per-Task Quantization Using LLMs' Hidden Representations
Nov 09, 2025

Large Language Models (LLMs) excel across diverse tasks, yet many applications require only limited capabilities, making large variants inefficient in memory and latency. Existing approaches often combine distillation and quantization, but most post-training quantization (PTQ) methods are task-agnostic, ignoring how task-specific signals are distributed across layers. In this work, we propose to use hidden representations that encode task-salient signals as a guideline for quantization. In order to fully utilize our innovative idea, this paper compares two new task-aware PTQ methods: Task-Aware Quantization (TAQ), which allocates bitwidths using task-conditioned statistics from hidden activations, and TAQO, which allocates precision based on direct layer sensitivity tests. From a small calibration set, these approaches identify task-relevant layers, preserving their precision while aggressively quantizing the rest. This yields stable task sensitivity profiles and efficient task-specialized models. Across models, TAQ and TAQO outperform the baselines; TAQ leads on Phi-4, while TAQO leads on Llama-3.1, Qwen3, and Qwen2.5. For instances, on Phi-4 it achieves 42.33 EM / 50.81 F1, far surpassing Activation-aware Weight Quantization (AWQ) (2.25 / 7.07), while remaining within < 1.0% of the original accuracy at lower average precision.
REMIND: Input Loss Landscapes Reveal Residual Memorization in Post-Unlearning LLMs
Nov 06, 2025Machine unlearning aims to remove the influence of specific training data from a model without requiring full retraining. This capability is crucial for ensuring privacy, safety, and regulatory compliance. Therefore, verifying whether a model has truly forgotten target data is essential for maintaining reliability and trustworthiness. However, existing evaluation methods often assess forgetting at the level of individual inputs. This approach may overlook residual influence present in semantically similar examples. Such influence can compromise privacy and lead to indirect information leakage. We propose REMIND (Residual Memorization In Neighborhood Dynamics), a novel evaluation method aiming to detect the subtle remaining influence of unlearned data and classify whether the data has been effectively forgotten. REMIND analyzes the model's loss over small input variations and reveals patterns unnoticed by single-point evaluations. We show that unlearned data yield flatter, less steep loss landscapes, while retained or unrelated data exhibit sharper, more volatile patterns. REMIND requires only query-based access, outperforms existing methods under similar constraints, and demonstrates robustness across different models, datasets, and paraphrased inputs, making it practical for real-world deployment. By providing a more sensitive and interpretable measure of unlearning effectiveness, REMIND provides a reliable framework to assess unlearning in language models. As a result, REMIND offers a novel perspective on memorization and unlearning.
Silenced Biases: The Dark Side LLMs Learned to Refuse
Nov 05, 2025Safety-aligned large language models (LLMs) are becoming increasingly widespread, especially in sensitive applications where fairness is essential and biased outputs can cause significant harm. However, evaluating the fairness of models is a complex challenge, and approaches that do so typically utilize standard question-answer (QA) styled schemes. Such methods often overlook deeper issues by interpreting the model's refusal responses as positive fairness measurements, which creates a false sense of fairness. In this work, we introduce the concept of silenced biases, which are unfair preferences encoded within models' latent space and are effectively concealed by safety-alignment. Previous approaches that considered similar indirect biases often relied on prompt manipulation or handcrafted implicit queries, which present limited scalability and risk contaminating the evaluation process with additional biases. We propose the Silenced Bias Benchmark (SBB), which aims to uncover these biases by employing activation steering to reduce model refusals during QA. SBB supports easy expansion to new demographic groups and subjects, presenting a fairness evaluation framework that encourages the future development of fair models and tools beyond the masking effects of alignment training. We demonstrate our approach over multiple LLMs, where our findings expose an alarming distinction between models' direct responses and their underlying fairness issues.
Representing LLMs in Prompt Semantic Task Space
Sep 26, 2025Large language models (LLMs) achieve impressive results over various tasks, and ever-expanding public repositories contain an abundance of pre-trained models. Therefore, identifying the best-performing LLM for a given task is a significant challenge. Previous works have suggested learning LLM representations to address this. However, these approaches present limited scalability and require costly retraining to encompass additional models and datasets. Moreover, the produced representation utilizes distinct spaces that cannot be easily interpreted. This work presents an efficient, training-free approach to representing LLMs as linear operators within the prompts' semantic task space, thus providing a highly interpretable representation of the models' application. Our method utilizes closed-form computation of geometrical properties and ensures exceptional scalability and real-time adaptability to dynamically expanding repositories. We demonstrate our approach on success prediction and model selection tasks, achieving competitive or state-of-the-art results with notable performance in out-of-sample scenarios.
Sparse patches adversarial attacks via extrapolating point-wise information
Nov 25, 2024



Sparse and patch adversarial attacks were previously shown to be applicable in realistic settings and are considered a security risk to autonomous systems. Sparse adversarial perturbations constitute a setting in which the adversarial perturbations are limited to affecting a relatively small number of points in the input. Patch adversarial attacks denote the setting where the sparse attacks are limited to a given structure, i.e., sparse patches with a given shape and number. However, previous patch adversarial attacks do not simultaneously optimize multiple patches' locations and perturbations. This work suggests a novel approach for sparse patches adversarial attacks via point-wise trimming dense adversarial perturbations. Our approach enables simultaneous optimization of multiple sparse patches' locations and perturbations for any given number and shape. Moreover, our approach is also applicable for standard sparse adversarial attacks, where we show that it significantly improves the state-of-the-art over multiple extensive settings. A reference implementation of the proposed method and the reported experiments is provided at \url{https://github.com/yanemcovsky/SparsePatches.git}
Hysteresis Activation Function for Efficient Inference
Nov 15, 2024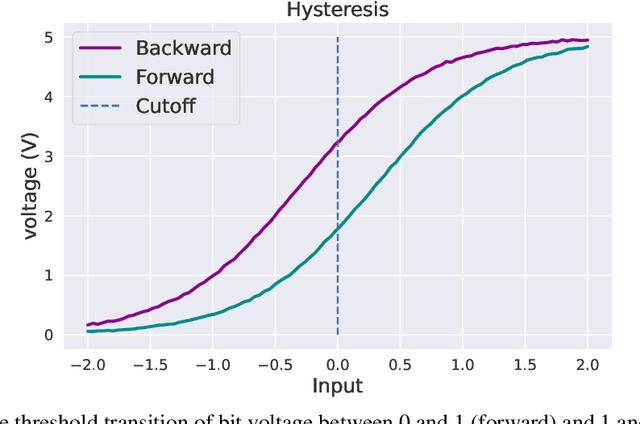
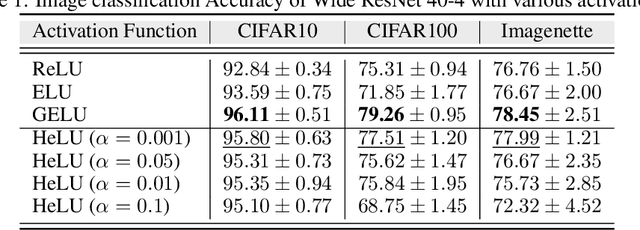

The widely used ReLU is favored for its hardware efficiency, {as the implementation at inference is a one bit sign case,} yet suffers from issues such as the ``dying ReLU'' problem, where during training, neurons fail to activate and constantly remain at zero, as highlighted by Lu et al. Traditional approaches to mitigate this issue often introduce more complex and less hardware-friendly activation functions. In this work, we propose a Hysteresis Rectified Linear Unit (HeLU), an efficient activation function designed to address the ``dying ReLU'' problem with minimal complexity. Unlike traditional activation functions with fixed thresholds for training and inference, HeLU employs a variable threshold that refines the backpropagation. This refined mechanism allows simpler activation functions to achieve competitive performance comparable to their more complex counterparts without introducing unnecessary complexity or requiring inductive biases. Empirical evaluations demonstrate that HeLU enhances model generalization across diverse datasets, offering a promising solution for efficient and effective inference suitable for a wide range of neural network architectures.
FBM: Fast-Bit Allocation for Mixed-Precision Quantization
May 30, 2022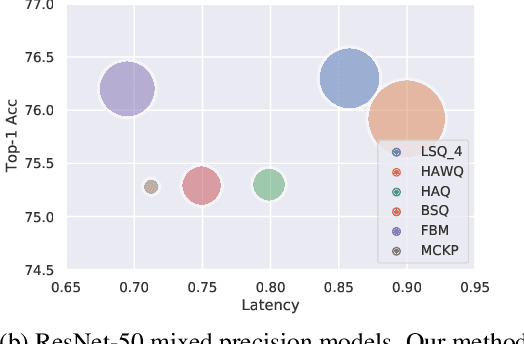
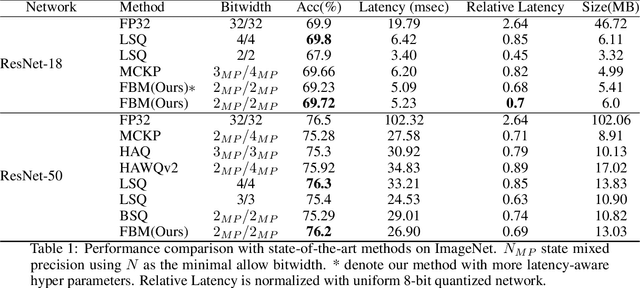
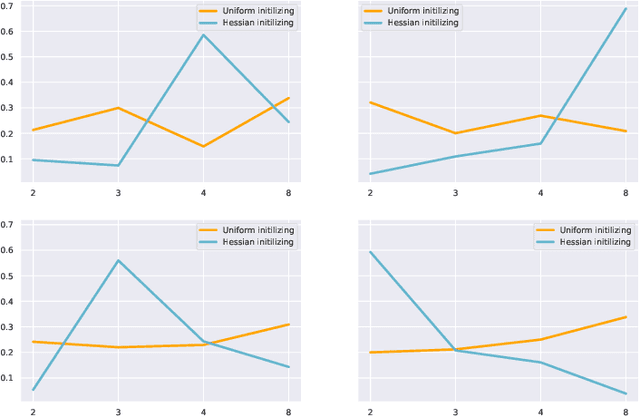
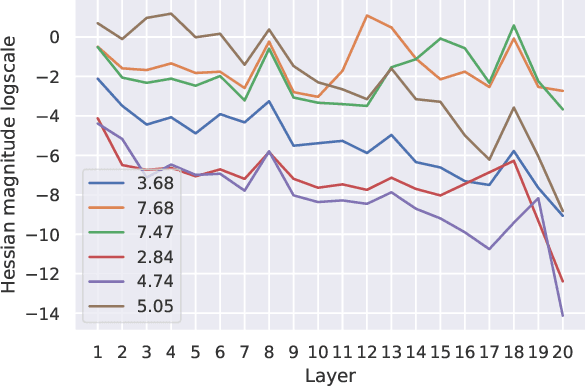
Quantized neural networks are well known for reducing latency, power consumption, and model size without significant degradation in accuracy, making them highly applicable for systems with limited resources and low power requirements. Mixed precision quantization offers better utilization of customized hardware that supports arithmetic operations at different bitwidths. Existing mixed-precision schemes rely on having a high exploration space, resulting in a large carbon footprint. In addition, these bit allocation strategies mostly induce constraints on the model size rather than utilizing the performance of neural network deployment on specific hardware. Our work proposes Fast-Bit Allocation for Mixed-Precision Quantization (FBM), which finds an optimal bitwidth allocation by measuring desired behaviors through a simulation of a specific device, or even on a physical one. While dynamic transitions of bit allocation in mixed precision quantization with ultra-low bitwidth are known to suffer from performance degradation, we present a fast recovery solution from such transitions. A comprehensive evaluation of the proposed method on CIFAR-10 and ImageNet demonstrates our method's superiority over current state-of-the-art schemes in terms of the trade-off between neural network accuracy and hardware efficiency. Our source code, experimental settings and quantized models are available at https://github.com/RamorayDrake/FBM/
Bimodal Distributed Binarized Neural Networks
Apr 05, 2022
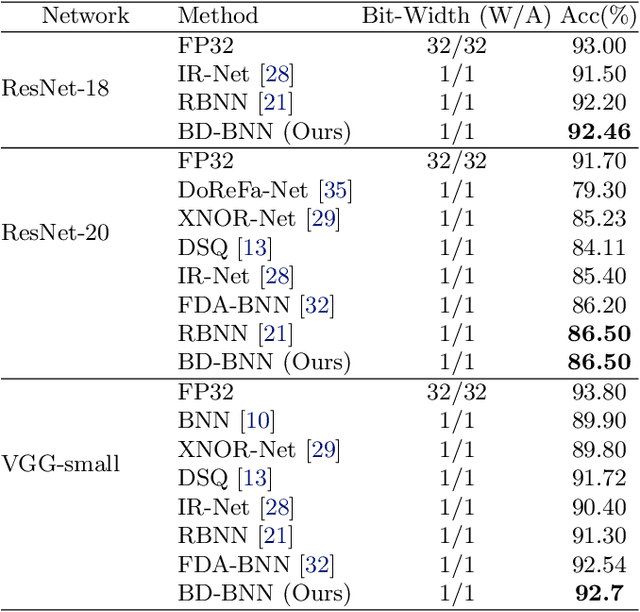

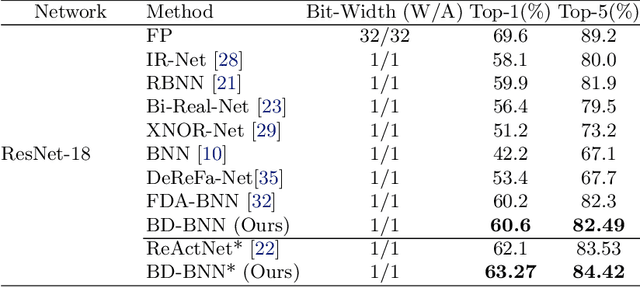
Binary Neural Networks (BNNs) are an extremely promising method to reduce deep neural networks' complexity and power consumption massively. Binarization techniques, however, suffer from ineligible performance degradation compared to their full-precision counterparts. Prior work mainly focused on strategies for sign function approximation during forward and backward phases to reduce the quantization error during the binarization process. In this work, we propose a Bi-Modal Distributed binarization method (\methodname{}). That imposes bi-modal distribution of the network weights by kurtosis regularization. The proposed method consists of a training scheme that we call Weight Distribution Mimicking (WDM), which efficiently imitates the full-precision network weight distribution to their binary counterpart. Preserving this distribution during binarization-aware training creates robust and informative binary feature maps and significantly reduces the generalization error of the BNN. Extensive evaluations on CIFAR-10 and ImageNet demonstrate the superiority of our method over current state-of-the-art schemes. Our source code, experimental settings, training logs, and binary models are available at \url{https://github.com/BlueAnon/BD-BNN}.